In an SAE system for automated- driving of Level 4, the driver would trust that the vehicle is driving safely and, consequently, may not pay attention to the driving situation. The driver could be texting, working, or even sleeping. Since critical failures may not occur in these systems, a suitable safety architecture is required.
The human trust of a machine must be met by the design of the L4 automated driving system as an ultra-high reliable system, i.e., this system may not fail more frequently than, say, 10^-8 failures per hour, which is about once every ten-thousand years. Such low failure rate ensures that there is a high probability that a driver will never experience a system failure of the automated driving system. Achieving this is a challenge, because components such as hardware, chips, and software - the building blocks of these systems - fail much more frequently. However, there is a rich body of engineering practice and scientific literature on how to construct ultra-highly reliable systems from less reliable components. For example, aerospace flight control systems are required to fail even less frequently.
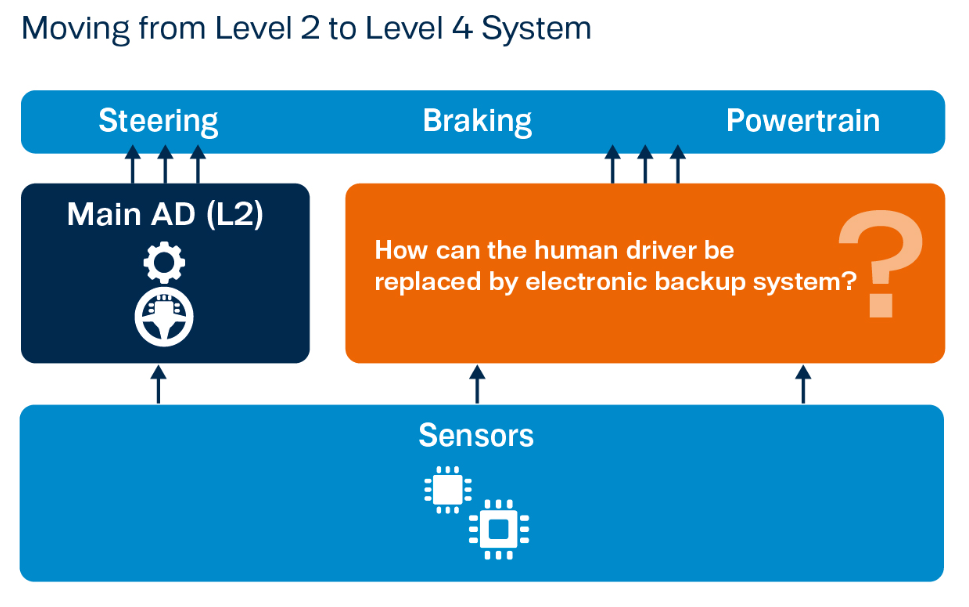
Figure 1: The Challenge of L4 Automated Driving
Ultra-highly reliable systems can only be constructed by means of appropriate decomposition of the overall system into subsystems and fault-containment units with a sufficient level of redundancy. Today’s automotive E/E architectures (E/E - electric/electronic) often do not follow such a systematic top-down design approach for ultra-highly reliable systems but are rather driven by the decomposition into functional domains. Subsystems and fault-containment units are often retrofitted into a finished system decomposition in a bottom-up manner. This latter approach entails high risks that the reliability goals cannot be met, and “architectural band-aids” must be introduced, typically resulting in dangerous emerging behavior as a side effect. In this paper we will review design challenges and provide a conceptual architecture for ultra-high reliable L4 automated driving systems.
The purpose of a safety architecture
Safety, as well as security, is a property of the overall system that is binary: an autonomous car is acceptably safe, or it is not. When we develop the system, this safety property translates into top-level requirements that guide the system implementation. This is typically a stepwise process in which multiple layers of requirements and designs are derived and we can always verify and validate, step by step, that design and implementation satisfy the respective requirements. This requirements-driven system development process has been proven to result in safe systems in adjacent industries, like aerospace, but it is also a common approach in the automotive domain. If safety was considered only late in system development, it would be introduced retrospectively by adding safety band-aid over safety band-aid with the risk that major safety gaps remain, and adequate system safety may not be achieved.
Safety standards and risk awareness vary around the world. In our society, the demand for safety is high. Annual accident statistics give an indication of the current societally acceptable fatality rate. Whether an autonomous car is acceptably safe once it causes fewer fatalities than human drivers or only when it is several orders of magnitude better is a topic of ongoing debate. We think that the systems we design should be at least a hundred times better.
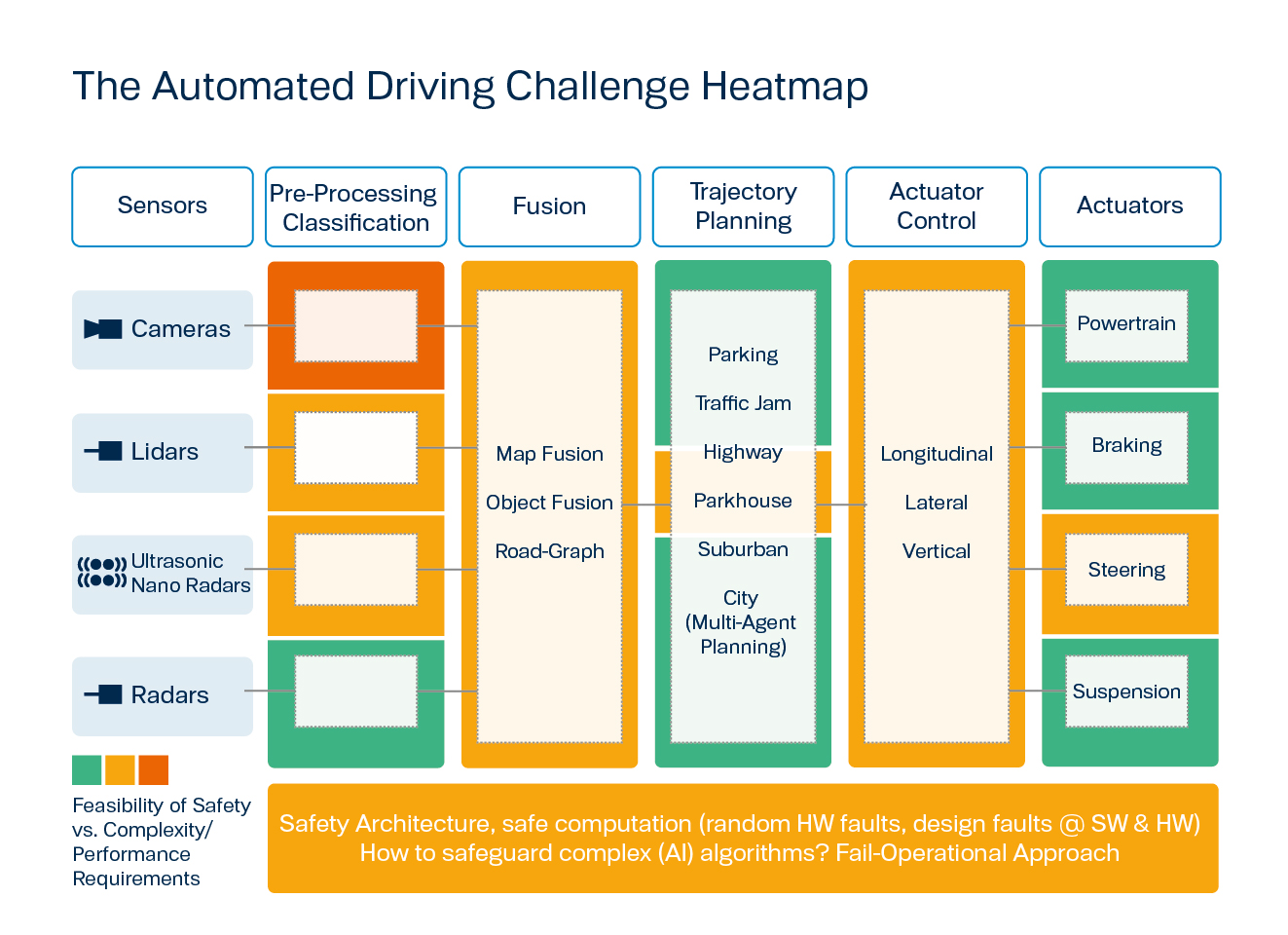
Figure 2: The Automated Driving Challenge Heat Map
It is a key requirement that an autonomous car continue to operate safely even when some part of it fails. This system property is called “fail-operational”. Designing such a fail-operational system is immensely difficult because there are many different parts that may fail in many different ways. Thus, the number of things that may go wrong is enormous. The only chance to manage this enormous failure space is to adhere to a safety architecture. This safety architecture defines so called fault-containment units (FCUs), i.e., parts of the system that may fail as a whole, and also defines the interactions between these FCUs. On this level of abstraction, the right safety architecture can already ensure that the failure of any FCU will not cause a complete system failure and that system will remain operational.
Fail-operational systems are common in the aerospace domain, allowing us to learn about possible adequate safety architectures. However, the functional complexity of an autonomous car is also unprecedented in the aerospace domain. Even though real autopilot systems do exist in aerospace, self-driving cars have a much more complex task to solve, simply because of the many more dynamic objects one finds on a street, compared to the sky. Moreover, autopilot systems that are used in aerospace must be monitored by trained pilots during critical flight phases, like landing, which means that these systems typically do not exceed the comparable level 2 in automated driving.
During cruise, autopilot systems might be compared to Level 3 systems: the pilot does not need to monitor the autopilot but must be present in the cockpit and must be ready to take over control within a couple of seconds. Moreover, autopilot systems that are used in aerospace must be monitored by trained pilots, which means that these systems typically do not exceed the comparable Level 2 in of automated driving. On the positive side, since the self-driving car is operating on the ground, once a failure is detected it can quickly enter a safe space like an emergency lane.
A Safety Architecture Proposal for Self-Driving Cars
Kopetz has proposed a safety architecture for self-driving cars in [1] depicted in Figure 3. Automated driving systems that follow this architecture can safely replace the human driver. Quite literally, these systems generate output that otherwise would be produced by the human driver: essentially the setpoints for the car's speed and direction. Even better, these systems will continue to operate even in presence of failures.
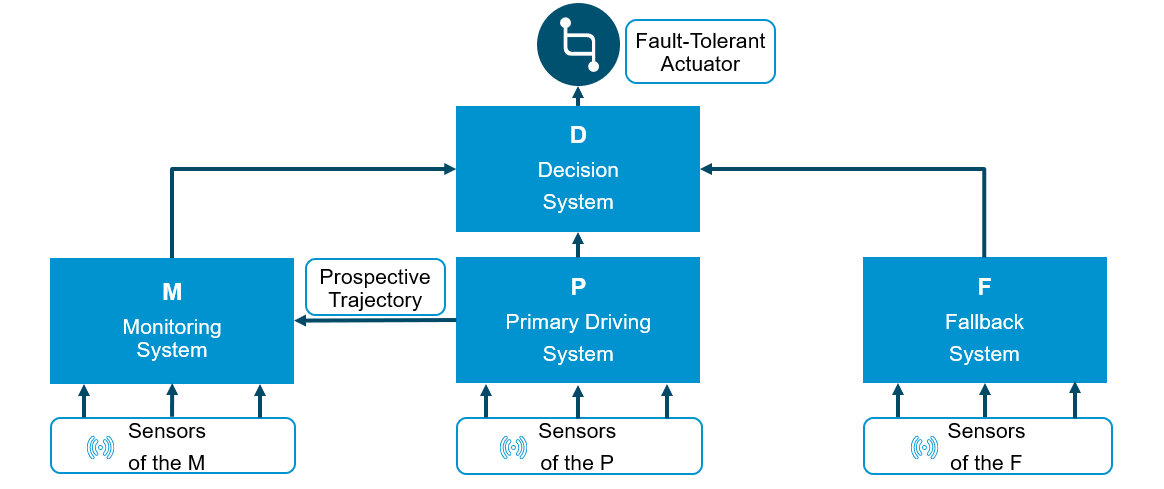
Figure 3: Architecture for a Driving Automation System
The architecture distinguishes four subsystems:
- Primary Driving System (P)
- Monitoring System (M)
- Fallback System (F)
- Decision System (D)
Both the Primary and the Fallback periodically produce output used to determine the behavior of the self-driving car. The Monitoring System (Monitor) monitors the output of both the Primary and the Fallback. The Decision System receives the Primary's and Fallback's output as well as that of the Monitor. In absence of failures, the Primary will provide its output to the Decision System, which will have that output checked by the Monitor. In a failure-free scenario, the Monitor will approve the Primary's output and inform the Decision System. The Decision System will then forward this Monitor-approved output to the receivers (e.g., the actuators). A simple protocol in the receivers selects one output per cycle.
The Primary, the Monitor, and the Fallback form one fault-containment unit (FCU) each. This means that if some portion of a subsystem fails, then we consider the complete subsystem faulty. For example, if the Primary was realized as a stand-alone electronic control unit (ECU) and let this ECU implement a special purpose chip for object recognition, then in the event this chip failing, the complete ECU is considered faulty.
A safety architecture must also define the FCUs' failure behavior. In our case, Primary, Monitor, and Fallback can fail arbitrarily: such a faulty system may send any sequence of messages on their interfaces to the Decision System. The Decision System itself is composed of two FCUs with limited failure behavior, which can be established by common fail-safe technologies like lock-step mechanisms.
Even in this rather simple architecture, there are many different failure scenarios. In some scenarios, for example, the Primary will fail to produce a safe output and the Monitor will detect this failure. In these scenarios the Decision System will forward the output of the Fallback rather than the output of the Primary. As there are many different failure scenarios, manual inspection of them all is cumbersome and error-prone: some scenarios may easily be overlooked or interpreted incorrectly. Thus, we have used model-checking to exhaustively explore all possible failure scenarios. We invented this approach almost twenty years ago in the context of network protocol verification in Steiner et al. [2]. Using exhaustive fault-simulation we have shown the Kopetz architecture is safe.
TTTech Auto's Architecture Analysis Toolbox
Exhaustive fault simulation is part of TTTech Auto’s Architecture Analysis Toolbox (including Markov modelling and Fault-Tree Analysis). Using TTTech Auto’s Architecture Analysis Toolbox enables us to efficiently analyze our clients’ safety architectures to identify weaknesses and to formally prove their safety. We can formally show that an architecture is free of single points of failures and can include a mapping of the abstract architecture to physical implementations.
References
[1] Kopetz, Hermann, “An Architecture for Driving Automation”, 2020, https://www.the-autonomous.com/news/an-architecture-for-driving-automation/.
[2] Steiner, Wilfried, John Rushby, Maria Sorea, and Holger Pfeifer. "Model checking a fault-tolerant startup algorithm: From design exploration to exhaustive fault simulation." In: International Conference on Dependable Systems and Networks, 2004, pp. 189-198. IEEE, 2004.
About the author

Wilfried Steiner, Dr.
Wilfried Steiner is the Director of the TTTech Labs which acts as center for strategic research as well as the center for IPR management within the TTTech Group. Wilfried Steiner holds a degree of Doctor of Technical Sciences and the Venia Docendi in Computer Science, both from the Vienna University of Technology, Austria.
His research is focused on dependable cyber-physical systems, in particular in the following domains: automotive, space, aerospace, as well as new energy and industrial automation. Wilfried Steiner designs algorithms and network protocols with real-time, dependability, and security requirements.
Wilfried Steiner has authored and co-authored over eighty peer-reviewed scientific publications and is inventor and co-inventor of twenty-five patent families with about another ten patent families pending. Wilfried Steiner has successfully participated in multiple national and international publicly funded research projects. In particular, from 2009 to 2012 Wilfried Steiner has been awarded a Marie Curie International Outgoing Fellowship that has been hosted by SRI International in Menlo Park, CA.
Wilfried Steiner also acted as editor for the SAE AS6802 standard (Time-Triggered Ethernet), served multiple years as voting member in the IEEE 802.1 that standardizes time-sensitive networking (TSN), and is currently member in the ISO TC 22 that develops standards for safe autonomous road vehicles.


